Chapter 11 TextMinig (W11-2)
11.1 개발자 키 받기
Create your application
- https://apps.twitter.com/ 방문하기
- Name은 다른 사용자들이 이미 지정한 것이면 안되므로, 길게 아무것나 작성
- Website는 접속이 가능한 사이트여야 함. (그래서 여기서는 테스트이므로 구글주소를 사용)
- call back은 공백
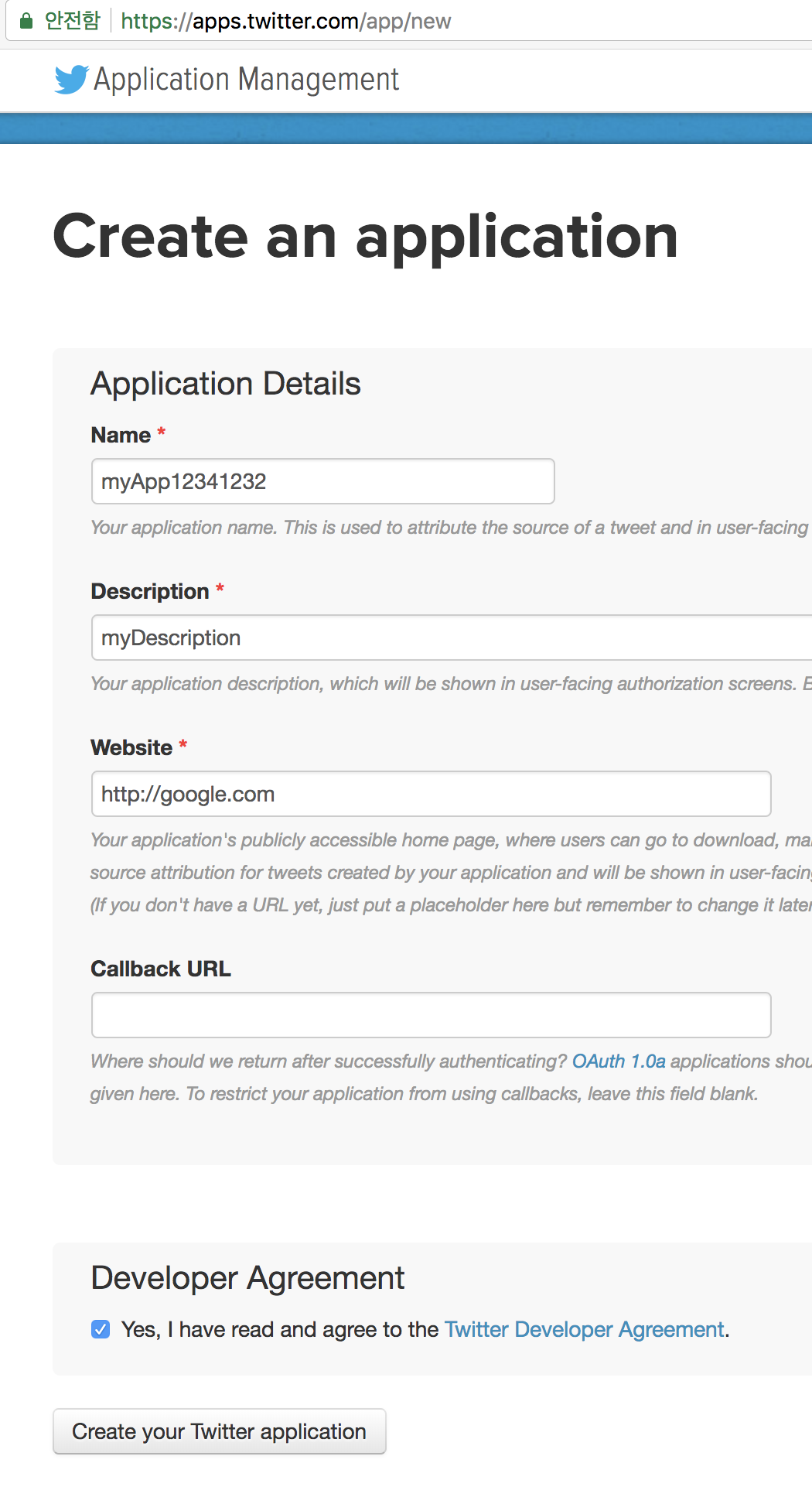
Figure 11.1: Create your application
Create my access token
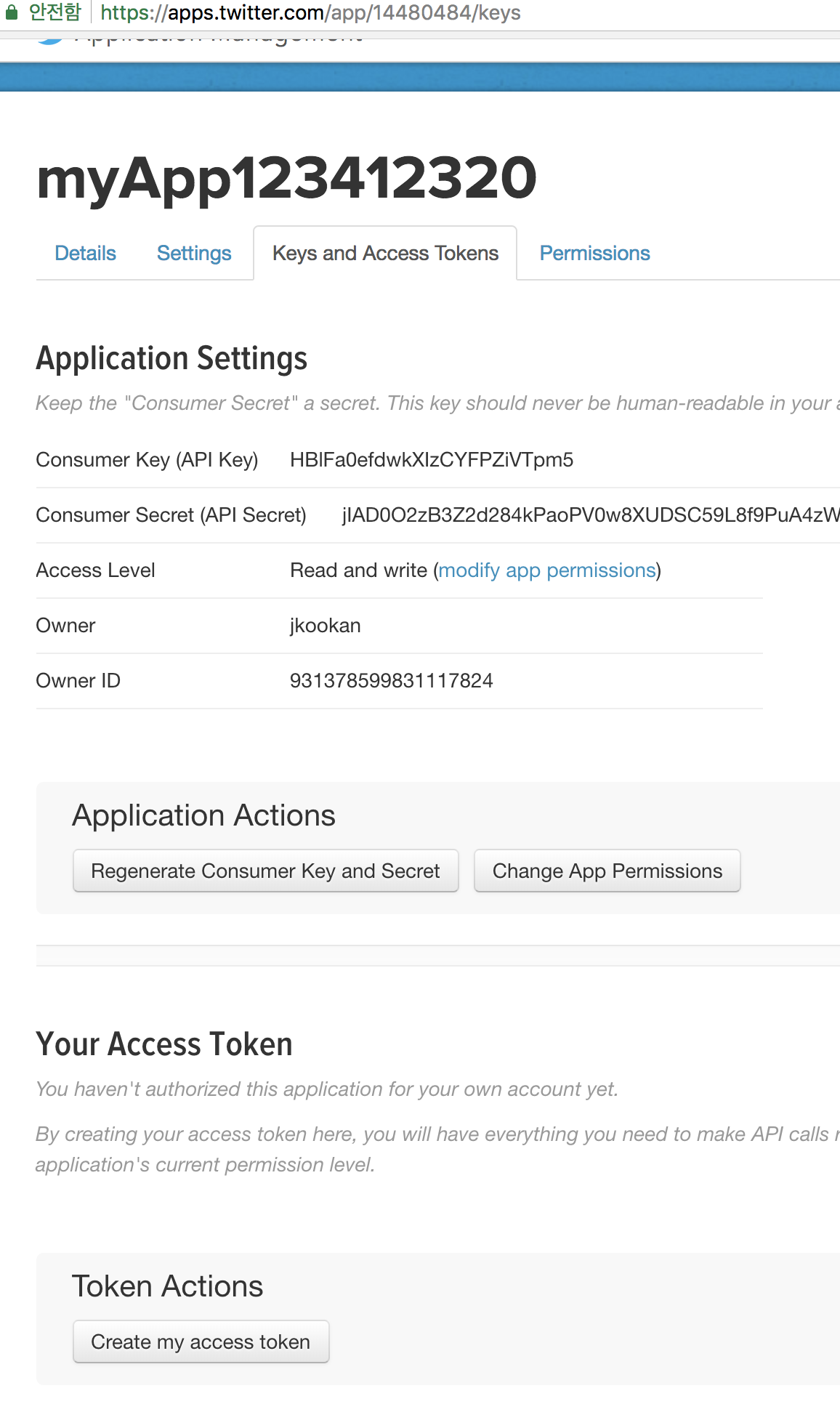
Figure 11.2: Create my access token
API 키, access 토큰 값 확인
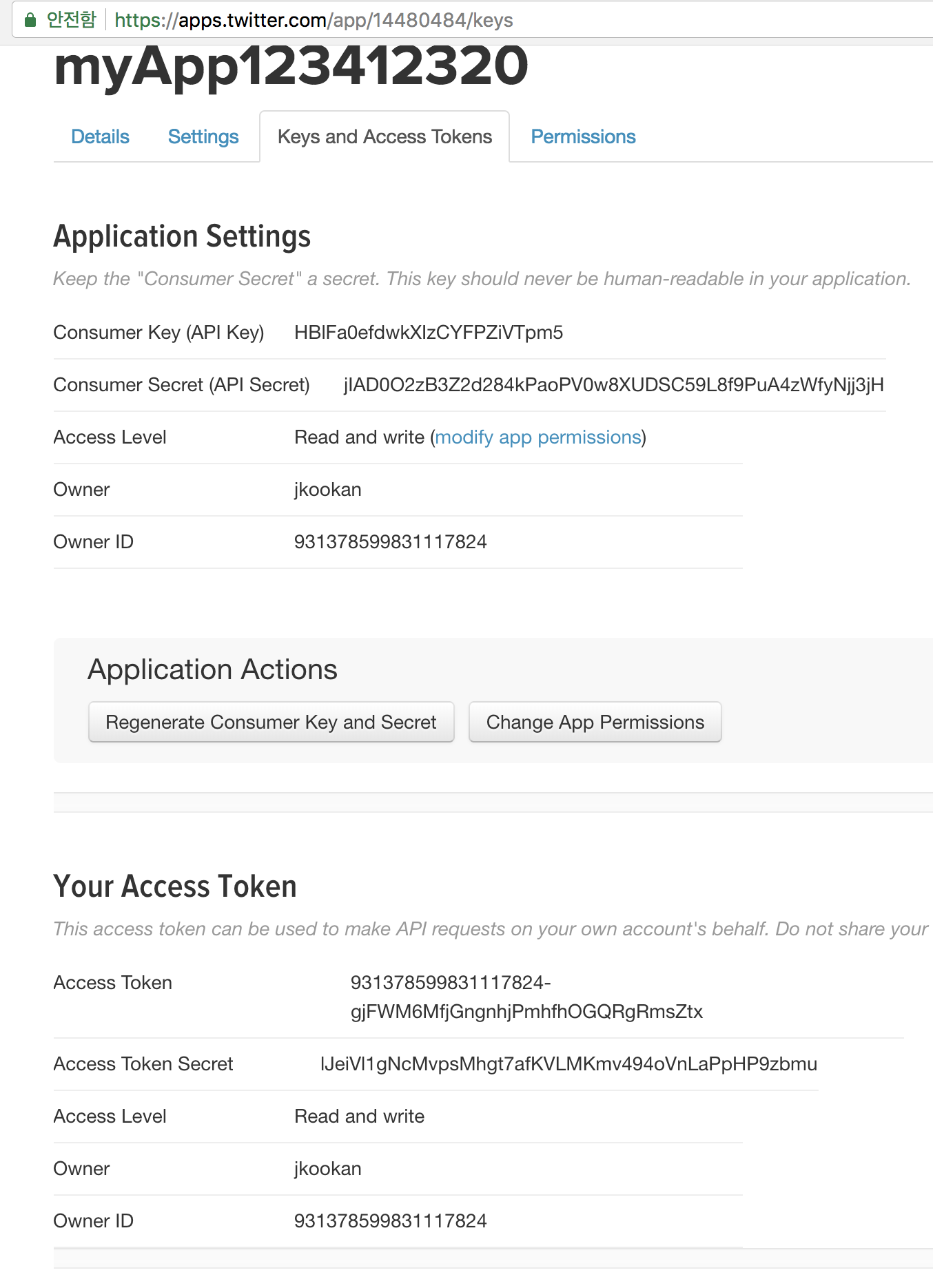
Figure 11.3: 키값
11.2 데이터 긁어오기
twitterR 패키지를 사용 (설치해야함)
- 콘솔창에 OAuth관련 질문이 나오면 1번을 선택
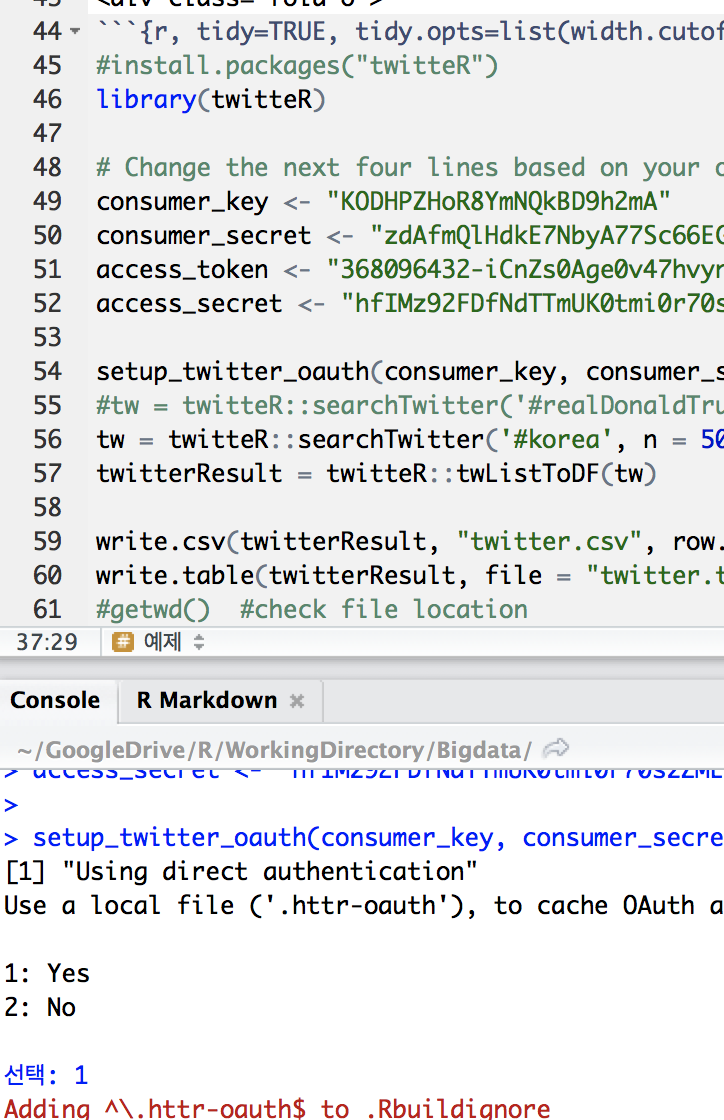
Figure 11.4: console 창 확인
- 트윗을 수집을 해서 데이터 프레임에 넣음 (twitterResult)
- head(twitterResult) 로 데이터를 출력을 해봄
- 텍스트 파일과 csv 파일로 working directory에 저장함
- 저장된 파일의 경로는 getwd()를 적용해서 확인
- 트위터에서 #korea 해시태그가 있는 트윗을 50개 출력, 2017년 11월 8일 이후
# install.packages('twitteR')
library(twitteR)
# Change the next four lines based on your own
# consumer_key, consume_secret, access_token, and
# access_secret.
consumer_key <- "KODHPZHoR8YmNQkBD9h2mA"
consumer_secret <- "zdAfmQlHdkE7NbyA77Sc66EGQMZ9q4W1IchtVQJVr8"
access_token <- "368096432-iCnZs0Age0v47hvynF08FSOxRhTOyzkz2UMy0gS0"
access_secret <- "hfIMz92FDfNdTTmUK0tmi0r70szZMELuJF6KAgBUP0w"
setup_twitter_oauth(consumer_key, consumer_secret, access_token,
access_secret)## [1] "Using direct authentication"# tw = twitteR::searchTwitter('#realDonaldTrump +
# #HillaryClinton', n = 10, since = '2017-11-08',
# retryOnRateLimit = 1e3)
tw = twitteR::searchTwitter("#아이유", n = 50, since = "2017-11-08",
retryOnRateLimit = 3)
twitterResult = twitteR::twListToDF(tw)
write.csv(twitterResult, "twitter.csv", row.names = TRUE)
write.table(twitterResult, file = "twitter.txt", sep = "\t")
# getwd() #check file location
head(twitterResult)## text
## 1 RT @930516n080918: 팔레트 서토콘 두번째 포토타임!!!\n\n#아이유 #팔레트\n\n함께여서 너무 좋았어요!!❤️\xed\xa0\xbd\xed\xb1\x8d\xed\xa0\xbd\xed\xb1\x8d https://t.co/t2XigqjQv9
## 2 RT @IUdotcom: 171209 2017 아이유 투어 콘서트 '팔레트' 서울공연 직캠 프리뷰 by.아기곰\n\n#아이유(@lily199iu) #IU #팔레트 https://t.co/QDMzGjlyz4
## 3 RT @IUdotcom: 171209 2017 아이유 투어 콘서트 '팔레트' 서울공연 직찍 샘플 by.배말\n\n#아이유(@lily199iu) #IU #팔레트 https://t.co/YKTJs5Ivdi
## 4 RT @IUdotcom: 171209 2017 아이유 투어 콘서트 '팔레트' 서울공연 직찍 샘플 by.배말\n\n#아이유(@lily199iu) #IU #팔레트 https://t.co/YKTJs5Ivdi
## 5 RT @Coowoo8: 171209 팔레트 뒷배경 약간 #아이유 #아이유콘서트 https://t.co/HkA0Z9kNsS
## 6 RT @Spinel_01: 171202 #아이유 '밤편지' 직캠 #IU fancam - Through the Night by Spinel https://t.co/anfuk6u1GQ https://t.co/7sBkh6AHoU
## favorited favoriteCount replyToSN created truncated
## 1 FALSE 0 NA 2017-12-10 04:51:31 FALSE
## 2 FALSE 0 NA 2017-12-10 04:51:31 FALSE
## 3 FALSE 0 NA 2017-12-10 04:51:23 FALSE
## 4 FALSE 0 NA 2017-12-10 04:51:20 FALSE
## 5 FALSE 0 NA 2017-12-10 04:51:14 FALSE
## 6 FALSE 0 NA 2017-12-10 04:51:13 FALSE
## replyToSID id replyToUID
## 1 NA 939719203715563520 NA
## 2 NA 939719200268046337 NA
## 3 NA 939719170035294208 NA
## 4 NA 939719154474532864 NA
## 5 NA 939719131984777216 NA
## 6 NA 939719125798043650 NA
## statusSource
## 1 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 2 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 3 <a href="http://twitter.com" rel="nofollow">Twitter Web Client</a>
## 4 <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>
## 5 <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a>
## 6 <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a>
## screenName retweetCount isRetweet retweeted longitude latitude
## 1 verxrys 142 TRUE FALSE NA NA
## 2 yoonekuk 369 TRUE FALSE NA NA
## 3 iusslime 243 TRUE FALSE NA NA
## 4 leejieunmylove 243 TRUE FALSE NA NA
## 5 kokora901 251 TRUE FALSE NA NA
## 6 thazin_94 140 TRUE FALSE NA NA데이터 확인
- Working directory에 가서 확인하기 –> getwd() 명령어를 콘솔창에서 실행
- RStudio 오른쪽의 Environment 탭에서 확인
Figure 11.5: twitterResult 오른쪽 테이블 아이콘 클릭
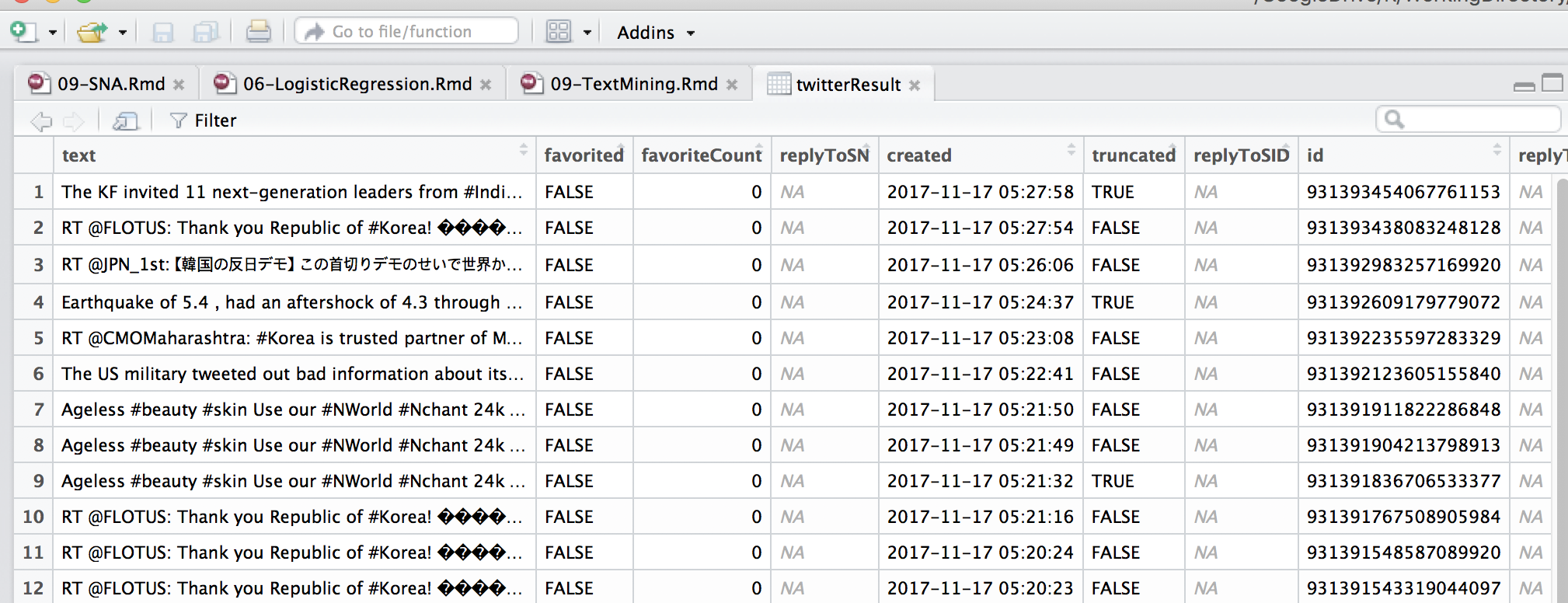
Figure 11.6: 데이터 확인
11.3 워드클라우드 출력 (한글)
- 위의 트위터 데이터가 twitter.txt로 저장되었으니 그 파일을 워드클라우드로 출력해보자
- 에러가 나오면 패키지들을 설치
- 위에서 예제로 아이유에 관한 트위터를 모았음
- 아이유를 명사로 등록하고, 관련으로 나올 유인나, 이효리도 명사로 등록
- 왜냐면 명사만 뽑아서 워드클라우드를 그릴 것이니, 유인나와 이효리가 나오도록 하는 것임
- 예제이므로 유인나와 이효리가 트위터 데이터에 있는지 없는지도 잘은 모르니 참조만 하세요
- 명사들의 출현 빈도를 계산할때, 카톡, 카카오톡이 따로 잡히면 안되므로 카톡을 모두 카카오톡으로 문자변경을 하여 카카오톡과 카톡을 출현빈도를 합침
- 아이유를 명사로 등록하고, 관련으로 나올 유인나, 이효리도 명사로 등록
- 한글 깨짐 해결 (문자가 네모로 나오면)
- 아래 소스에서 AppleGothic을 MalgunGothic로 변경
# Install wordcloud package and related packages.
# install.packages('KoNLP') # For Korean
# install.packages('SnowballC')
# install.packages('wordcloud')
# install.packages('RColorBrewer')
# install.packages('plyr') install.packages('stringr')
# install.packages('ggplot2')
library(KoNLP)## Checking user defined dictionary!library(SnowballC)
library(RColorBrewer)
library(wordcloud)
library(plyr)##
## Attaching package: 'plyr'## The following object is masked from 'package:twitteR':
##
## idlibrary(stringr)
library(ggplot2)
# Use Korean dictionary.
useSejongDic()## Backup was just finished!
## 370957 words dictionary was built.# 명사로 등록
mergeUserDic(data.frame("아이유", "ncn"))## Warning: 'mergeUserDic' is deprecated.
## Use 'buidDictionary()' instead.
## See help("Deprecated")## 1 words were added to dic_user.txt.mergeUserDic(data.frame("유인나", "ncn"))## Warning: 'mergeUserDic' is deprecated.
## Use 'buidDictionary()' instead.
## See help("Deprecated")## 1 words were added to dic_user.txt.mergeUserDic(data.frame("이효리", "ncn"))## Warning: 'mergeUserDic' is deprecated.
## Use 'buidDictionary()' instead.
## See help("Deprecated")## 1 words were added to dic_user.txt.# Read text data from text file.
parsed <- readLines("/Users/jace/GoogleDrive/R/WorkingDirectory/Bigdata/twitter.txt",
encoding = "UTF-8")
# 명사추출
parsed <- sapply(parsed, extractNoun, USE.NAMES = F)
# Unlist and apply filter. 2자 이상
parsed <- unlist(parsed)
parsed <- Filter(function(x) {
nchar(x) >= 2
}, parsed)
# 문자 바꾸기, 카톡을 카카오톡으로, ㅋ와ㅎ는 삭제
parsed <- str_replace_all(parsed, "[^[:alpha:]]", "") # 알파벳 삭제
parsed <- str_replace_all(parsed, "[A-Za-z0-9]", "") # 숫자 삭제
parsed <- gsub("카톡", "카카오톡", parsed) # 카톡 --> 카카오톡
parsed <- gsub("ㅋ", "", parsed) # ㅋ --> 삭제 (따옴표 안에 아무것도 없으므로)
parsed <- gsub("ㅎ", "", parsed) # ㅎ --> 삭제 (따옴표 안에 아무것도 없으므로)
# Write parsed string as unlist and read table from the
# temporary file.
write(unlist(parsed), "tempfile.txt")
text_table <- read.table("tempfile.txt")
# Create table data with word count
word_Count <- table(text_table)
# Create data.frame from table data.
terms <- data.frame(word_Count)
# Change column name.
names(terms) <- c("word", "freq")
# Sort the matrix data according to rowsums as desc order.
terms <- arrange(terms, desc(freq))
# Extract N items from head top N. topN <- head(terms,
# 200)
# Set a random seed.
set.seed(1)
library(extrafont)## Registering fonts with Rtheme_set(theme_gray(base_family = "AppleGothic")) #윈도우일 경우 AppleGothic을 MalgunGothic로 고치세요
wordcloud(words = terms$word, freq = terms$freq, min.freq = 0.32,
max.words = 400, random.order = FALSE, rot.per = 0.25,
colors = brewer.pal(8, "Dark2"), family = "AppleGothic") # 본인의 컴퓨터가 윈도우일 경우 AppleGothic를 MalgunGothic로 변경 
# 바차트 (단어 빈도수)
terms2 <- arrange(terms, desc(freq))
top10 <- head(terms2, 50)
# 상위 20개만 보여주기
ggplot(head(arrange(top10, -freq), 20), aes(x = reorder(word,
-freq), y = freq)) + geom_bar(stat = "identity") + theme(axis.text.x = element_text(family = "AppleGothic")) # 본인의 컴퓨터가 윈도우일 경우 AppleGothic를 MalgunGothic로 변경